I immediately found an “exciting start of the year challenge” for myself.
So my following subdirectory A2 has disappeared.
└─ Directory A
… ├─ Subdirectory A1
… ├─ Subdirectory A2
Luckily I have a backup of my data. This was encrypted with Cryptomator.
But how do I find the A2 subdirectory in the backup to restore it? Of course I know the name of directory A. I can easily restore this too. However, I still don’t get the subdirectory A2 with that restore. I think I have to restore subdirectory A2! But I don’t know what the encrypted name of the subdirectory A2 was in the past?
According to my current understanding, it is not possible to restore the subdirectory A2, or can someone help me please?
Maybe there is already a topic like this, unfortunately I couldn’t find it, so feel free to send me the link.
Hey there, until someone more knowledgeable than me comes to help you, could you mention the version of cryptomator that you are using and also clarify some details about your backup, is it an identical copy of the entirety of the encrypted vault, which was made/copied directly from a working version of the vault before that folder disappeared? If you add the backup vault to cryptomator and open it, does it have all the files as expected?
I am trying to understand how exactly you tried restoring the files, was it by copying some missing encrypted files by comparing the two versions or something else?
• Yes, it is an identical copy of the entirety of the encrypted vault and yes it was copied directly from a working version of the vault before that folder disappeared or accidentally deleted
• For me it is not possible to add the entire backup. It’s 4 TB and it’s a backup in the cloud.
• So far I have always loaded exactly the file I needed from the backup. That’s how I wanted to do it this time too. Only this time it wasn’t a file, this time it is a directory. And now I don’t know how to find the correct directory - cry
I have had to do something similar 2-3 times, I had to locate files that were different between local copies of my backups that were supposed to be identical. I did not use any software to automate this, I just manually compared folder stats (file and folder numbers) starting from root folders and then going one level deeper within the folder that showed a discrepancy until I found the actual subfolder/file that had to be updated.
The differences here are:
your folder is online and depending on whether your cloud provider can show this info quickly and easily, it might take much more time than if it was a local backup.
you will have to make sure to re-create the folder structure exactly as it should be based on the working backup, including those 2-letter folders that usually contain subfolders with your encrypted files, then add the missing encrypted files in the final subfolders at the end.
My assumptions for this to work are (correct me if wrong):
Your working backup version in the cloud has NOT autosynced the missing folder, so it still has it where it should be.
If anything else goes wrong (e.g. you accidentally move or delete more encrypted files during this process), then you are sure you have a complete and working backup as a worst-case full restore.
Hopefully someone from the team can give you better advice (I am just a user). But if you can see all the folder info it should be easy enough to do manually so that you don’t have to wait longer for an answer during holidays. For local backups with large number of folders/files it takes me 5-10 minutes to locate a file. Your case is a bit harder but should be doable. You can even check many folders at once (e.g. for 10 folders check 5+5 folders instead of one at a time, then split the 5 to 2+3, then do the 2 or 3 one by one.
Based on the above and the folder info that your cloud provider shows, do you think this is doable in your case or is there something that prevents this?
Beyond Compare is a cross platform data comparison application. This applies to directories. It also has a Synchronize/‘sync base folders’ function. FTP/S, SFTP, S3, WebDAV, Dropbox is supported, license dependant. Conveniently, their beta 5 also features a dark mode. A 30 day trial is available.
First of all, thank you very much for your suggested solutions.
So one suggestion leads straight to the next suggestion and then my own ideas come
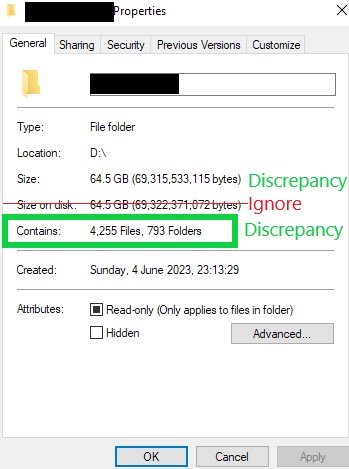
Anyway, I have about 100,000 directories and 1 million files. That’s why I prefer the automatic version
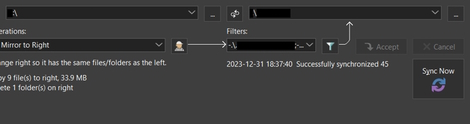
The note about Beyond Compare gave me the idea of using the tool Total Commander and its function “Synchronize directories”, because I already used that in the past. In fact, Total Comander listed all the deleted directories and files for me, that works very well
However, my backup is 6 months old. Since then, many directories have been deleted - around 100 of them. Now I am trying to exclude the wrong directories based on the number of files in the directory and their size
If anyone knows of an easier method, please let me know
Do you have access to a Linux-based computer? Comparing the directory names, files of your current dataset against the 6 month old set can be done by outputting each set’s respective directory listings into a text file. The resulting directory list text file can be compared against the other.
find $myDirectoryHere -type d | tee $my_name_of_this_dataset_here_-_directories.txt
In Beyond Compare one would use the ‘Diffs’ function.
Further filtering by pipes can be used based on file sizes I’m sure but that would be dependant on what you expect the proper directories to contain would contain. I would attempt so after having a clear view of what are the missing directories.
Also, rsync --ignore-existing -razv --checksum --progress might be of value. Run it from the 6 month old dataset directory with --dry-run to see what would be sync’d before committing to changing your current/main dataset.